Introduction
In this post, I will share the results of a topic modeling analysis using Latent Dirichlet Allocation (LDA) on a corpus derived from The Project Gutenberg eBook of Moby-Dick.
Methodology
The analysis followed these key steps:
- Text Collection: A sample of text from "The Project Gutenberg" in the Internet (https://gutenberg.org/files/2701/2701-0.txt) was compiled, encompassing various key events and characters from the series.
- Text Preprocessing: The text was cleaned by converting to lowercase, removing punctuation, numbers, stopwords, and applying stemming.
- Document-Term Matrix (DTM) Creation: The cleaned text was converted into a Document-Term Matrix.
- LDA Model Fitting: The LDA model was fitted with 5 topics.
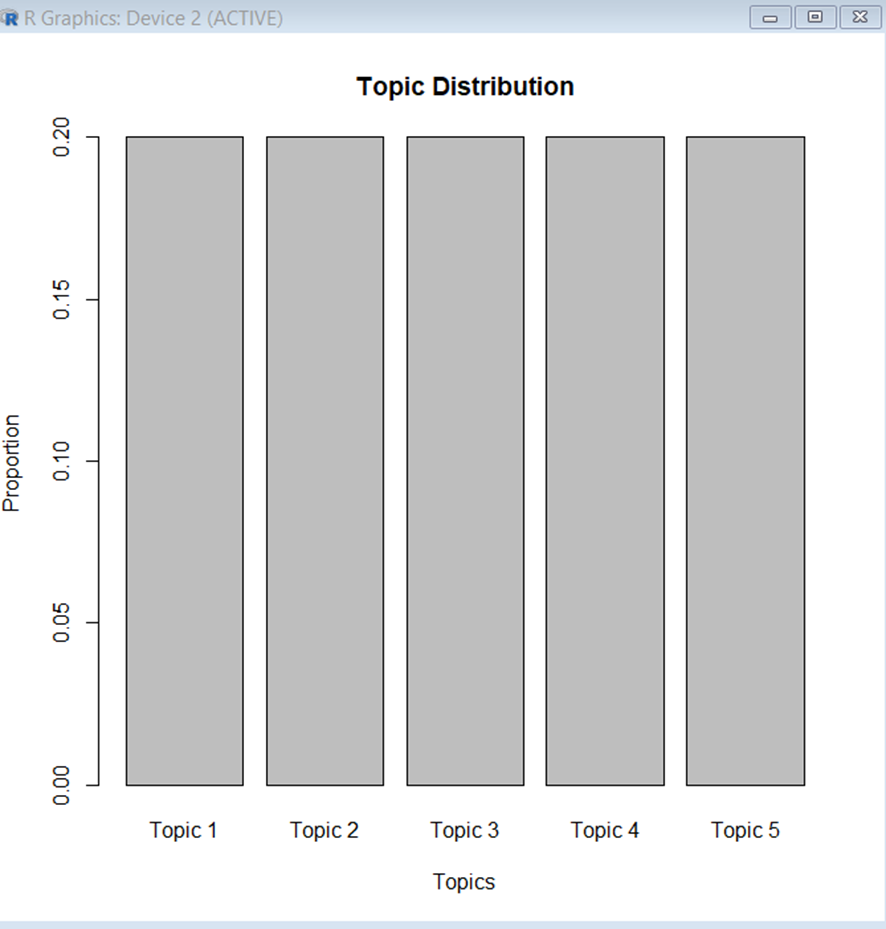
- Visualization: The results were visualized using bar plots for the top terms of each topic, a word cloud for the entire corpus, and a bar plot showing the topic distribution across the corpus. An interactive view Interactive Visualization with LDAvis was also created.
Results

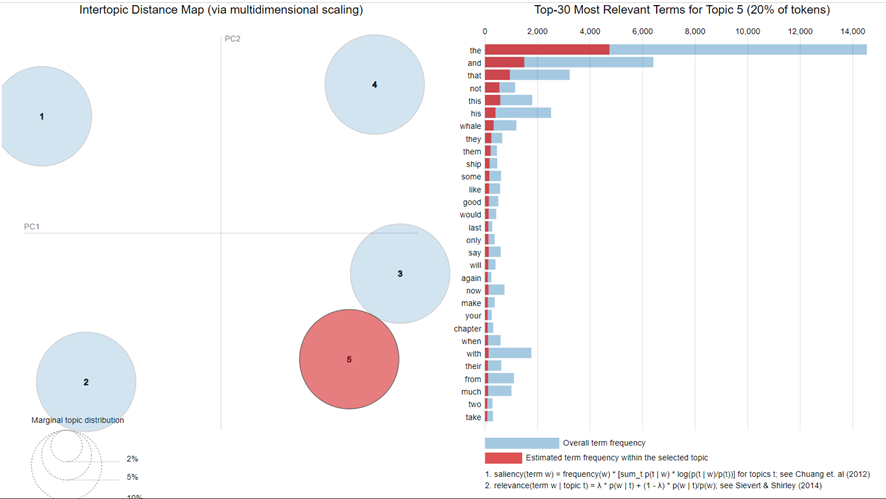
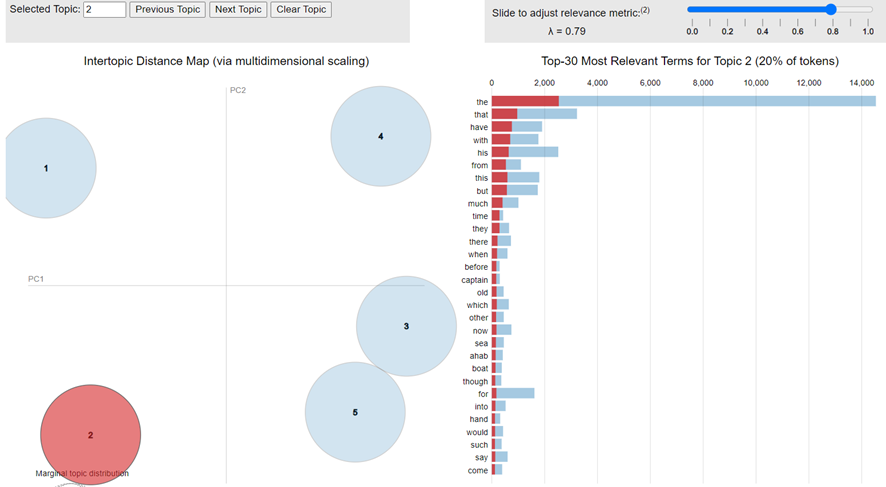
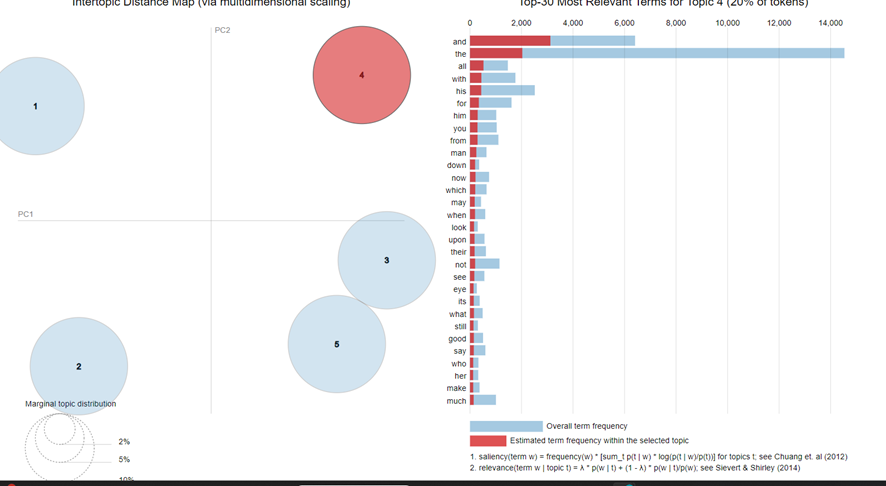
From here, I show the interactive graph where we can select the topics with Slide to adjust relevance metric:Topic 1
Topic 2
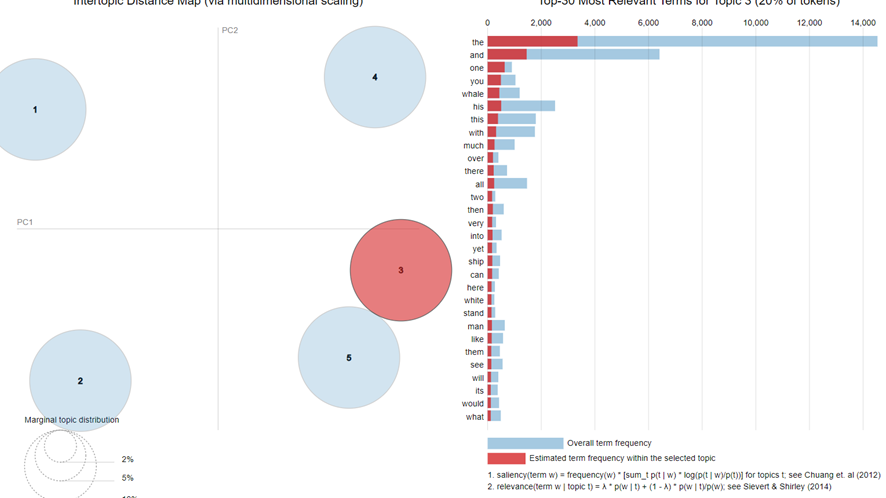
Topic 3
Topic 4
Topic 5