The topics identified through the LDA model capture prominent themes in the dataset focused on text mining and computational linguistics. The identified themes include "deriving high-quality information from text," "statistical pattern learning," "text structure analysis," and "linguistic feature extraction." The word clouds highlighted terms like "text mining," "analytics," "patterns," "linguistics," and "learning," emphasizing their significance within the analyzed documents. The topic distribution graphs illustrate how these themes are distributed across the dataset, revealing the diverse applications and complexities inherent in text mining and computational linguistics.
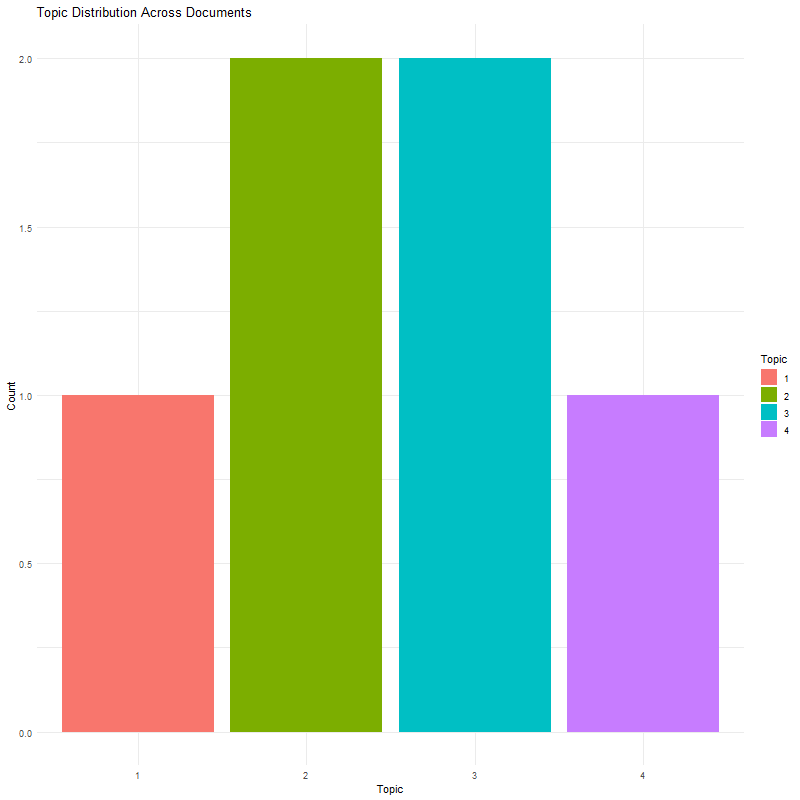
Dataset focused on text mining and computational linguistics
de către Marina Baltar-
Număr de răspunsuri: 5
Ca răspuns la Marina Baltar
Re: Dataset focused on text mining and computational linguistics
de către Nuno Rolo-
Great job
Ca răspuns la Marina Baltar
Re: Dataset focused on text mining and computational linguistics
de către Mário P Carvalho-
Very clear!
Ca răspuns la Marina Baltar
Re: Dataset focused on text mining and computational linguistics
de către João Filipe Moreira Veríssimo-
Well done!
Ca răspuns la Marina Baltar
Re: Dataset focused on text mining and computational linguistics
de către Nuno Baptista-
Hello Marina. Clear and information well presented. good job.
Ca răspuns la Marina Baltar
Re: Dataset focused on text mining and computational linguistics
de către Ana Guerreiro-
Nice job,
I reaaly like the clean way you present your results.
Regards,
Ana Guerreio
I reaaly like the clean way you present your results.
Regards,
Ana Guerreio